데이터 사이언스 모델링이란? – Data Filtering

학부 3학년 때다. 경영학과 수업 중에 우리과 전공으로 인정되는 몇 안 되는 수업 중 하나인 재무관리 수업 첫 시간으로 기억한다. 기업들의 Financing이 기업 가치 평가, 경영 의사 결정에 어떤 영향을 미칠 수 있는지에 대한 내용을 다루는 수업이었는데, 고학년 거시경제학 수업에서 ABS로 리파이낸싱하는 부분을 이해하는데 도움되는 수업이라는 말을 듣고 큰 기대를 하고 수업에 들어갔다.
다른 과 수업을 처음 들어서 주변 눈치를 슬쩍슬쩍 보고 있었는데, 뒷자리에 앉은 애들이 “이거 들어야 주식투자하는데 도움 된다며?” “이동 평균선이 골든 크로스 하는거 같은 내용 가르치는거야?” 같은 대화를 나누는걸보고 잠깐 수업을 잘못 들어왔나는 생각을 했었다.
아니나 다를까, 중간고사 칠 무렵이 되니 그 친구들은 수업을 억지로 나오는 티가 났고, 기말고사 칠 무렵이 되니 수업 잘못 골랐다고 불평을 잔뜩하더라.
런던에서 Financial Economics 석사 수업을 들을 때도 마찬가지였다. 그 수업, 아니 Finance의 가장 근본 철학인 “가격에는 모든 정보가 다 들어있다”, “Arbitrage는 장기간 존속할 수 없다” 같은 내용을 미시경제학과 수학적인 방법으로 증명하는 수업을 들으며 석사 프로그램을 잘못 골랐다고 불평하던 동기들을 꽤나 봤었다.
저런 수업을 들을 때는 이론이랑 실무랑 무슨 관계가 있냐고 불평하는 그들의 생각에 쬐끔 공감을 했었는데, 더 실력이 쌓이면서 그 이론이 어떻게 실무에 쓰이는지를 보고나니, “실무”를 주장하는 사람들이 얼마나 조악한 수학 실력으로 회사에서 “버티고” 있는지를 알게 되었다.
투자은행 다니던 시절, 재무관리 때 할인율 계산하는 공식을 그대로 외우기만 했던 Counterparty랑 기업 매각/인수 가격 모델을 놓고 한번 붙었던 적이 있는데, 자기 모델에 쓴 숫자에 대한 근거를 하나도 못 말하는 “꿀먹은 벙어리”(Read “영어 실력으로만 뱅킹 들어온 바보”)를 만났던 기억이 있다. 파생상품 가격 계산하는 모델을 볼 때도 단순하게 공식만 외워서 A상품의 가격을 넣으면 B상품의 가격이 나오는 줄만 알던 멍텅구리가 만든 ELS 파생상품이 특정 조건이 발생할 경우에 회사에 어마어마하게 큰 손실을 주는 걸 지적해줬던 적도 있다. 그러니까 책임회피할려고 그냥 다른나라에서 쓰는 상품을 그대로 베껴와서 쓰는거겠지ㅠㅠ
똑같은 경우를 데이터 사이언스 업무나 강의 중에도 곳곳에서 보는데, 요즘 그들을 “꼰대”라고 부르고 있다. 그 분들은 “실무”가 중요하다면서 “실무에서 쓰는 코드”를 달라고 몰아세우고, “이론 같은건 필요없다”고 주장들을 한다. 정작 문제가 생기는 경우를 보여주면서 이론적인 배경을 알아야되는 내용을 설명해주면, 자기가 알고 있는 내용이랑 다르다면서 학부 선형대수학도 모르는 망발을 읊어대기도 한다. 혼자서 저러면 시험 점수만 좀 낮게 받고 끝나겠지만, 저런 수준으로 회사 모델을 만들어 놓으면 심한 경우에 회사가 망할텐데?

사기 클릭 & 인스톨 (Fraud Click & Install) 잡아내기
전 직장에서 사기 클릭을 잡아내는 알고리즘을 고민하던 시절에 봤던 내용이다. 다른 회사들은 어떻게 접근할지 궁금해서 App 관련으로 DMP 사업을 하고 있는 글로벌 회사들이 소개해놓은 알고리즘을 살펴봤다. 물론 회사 기밀이니 자세한 내용을 공개해놓지는 않았지만, 어느 한 회사의 사기 인스톨 잡아내는 시스템을 보고 적잖이 충격을 먹었었다.
한 시간에 원래 X개의 인스톨이 발생하는데, 그거보다 더 많이 발생하면 “사기”라고 잡겠단다. 갑자기 다른 채널을 통해서 App 인스톨이 더 많이 생긴 경우에는 전부 다 “사기”라고 잡히겠네? 그건 또 내부적인 알고리즘이 있어서 분류를 할 수 있다는 식으로 두루뭉술하게 써 놨는데, 내부적인 알고리즘은 그냥 인간이 눈으로 보고 “사기”인지 아닌지 판단하겠다는 뜻이라고 봐도 무방할성 싶더라. 대충격이었다. 도대체 저 회사 Data Scientist는 아직까지 안 짤린 이유가 뭔가? 3류 로컬회사도 아니고, 글로벌 탑 티어 회사가 저런 모델을 쓰다니?
필자가 수업 시간에 소개하듯이, 당시 필자가 만들었던 모델은 클릭 or 인스톨 데이터의 주기 (Cycle)에 해당하는 부분과 노이즈 (Noise)에 해당하는 부분을 통계적인 필터링으로 분리한 다음, 그 주기를 Frequency 로 바꿔서 이상 Frequency가 발생하는 경우를 “사기일지도 모른다”고 잡아내는 방식으로 구성되어있다. 필터링이라는게 어지간한 학부 수업에서 다루지 않을수도 있지만, 사실 기본적인 시계열 통계학을 활용하는 방법 중 하나에 불과하다.
저런 수준의 회사가 협력사가 되면 빡침을 참기가 참 힘들어진다. 한번도 저런 모델링이라는걸 생각해본 적이 없는 사람들, 단순하게 평균치만 보면서 1차원의 숫자와 그래프로 살았던 사람들에게 분산과 표준편차도 아니고 필터링과 Frequency가 나오니 어떻게 이해를 할까? 모델을 이해 못하는 그들이 이해되지만, 한편으로는 학부와 석사시절에 수업들에 불평을 늘어놓던 친구들이 오버랩이 된다. 수업에 배우는 모델을 이해해본 적이 없기 때문에 회사 사정에 맞춰서 모델을 적절하게 변형해서 쓴다는 개념이 없는 것이다. 비지니스에서 누군가의 행동이 “이해”된다고해서 그들의 말도 안 되는 요구를 들어주지는 않는다. “바보”라고 판단되면 “무시”할 뿐이다.
데이터 사이언스 모델링 예시 – 로봇 청소기(?)
이미지 인식 같은 Low noise 데이터를 제외하면 거의 대부분의 데이터 기반 작업은 High noise 데이터를 여러가지 방식으로 전처리 (pre-processing)하는데서 시작한다. 그 중 저 위의 클릭 데이터 처리에 활용했던 Kalman filter를 다른 데이터 사이언스 프로젝트에 도입하는 예시 하나를 살펴보자.
거실에 로봇 청소기가 하나 있고, 그 청소기가 바퀴의 움직임에 대한 정보 + GPS 정보가 있다고 가정해보자. 참고로 바퀴의 각도와 속력으로 움직인 거리를 100% 맞출 수 없고, 실내에서 GPS 정보는 부정확하다. (KAIST에서 실내 GPS의 오차 보정을 위한 연구를 하고 있다. 관련논문) 말을 바꾸면, 오차가 가득 포함된 두 데이터를 바탕으로 로봇 청소기가 어디까지 움직였는지에 대한 “추측”을 해야된다는 뜻이다. 당연히 오차를 보정하기 위해서 오차 가득한 데이터를 Pre-processing 하고나서 결합을 시켜야한다. 데이터가 시간이 흐름에 따라 변하고 있고, 때로 주기적인 패턴이 나올 것이기 때문에 Kalman filter를 쓸 수 있는 매우 좋은 예시라고 생각된다.
오차를 제대로 보정하고 있는지 self-feedback을 줘야하니 여기에 Bayesian 모델링 아이디어를 추가해보자. 참고로 Bayesian 통계학은 기존의 데이터에서 나온 값을 Prior로 놓고, 새로운 데이터가 추가될 때 단순히 1/n의 가중치가 아니라 새로운 가중치로 기존 모델에 대한 “신뢰도” or “믿음” (Belief)를 바꾸는 통계학적 모델링 작업을 말한다. 다른 글에서도 언급했듯이 같은 아이디어가 자율주행차에도 도입되고 있다.
Kalman filter + Bayesian으로 위치 추정하는 법
필요한 가정
x값이 매번 새롭게 입력되는 바퀴 움직임의 정보, y값은 GPS 센서가 가르쳐주는 정보라고 생각해보자. 오차값이 정규분포를 따른다고 가정하면, 아래의 식으로 정리할 수 있다.
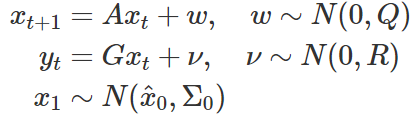
방금전의 바퀴 움직임이 다음 바퀴 움직임에 영향을 주는 정도를 A로 표현한 것이고, 바퀴 움직임에 따라 GPS 위치가 변화되는 정도를 G로 표현했다고 보면 된다. Q와 R은 그렇게 “추측”한 값이 어느 정도의 오차를 가질 것인지에 대한 가정이다. (보통 기존 데이터에서 뽑은 수치를 활용한다.)
Kalman filter에 의하면 위의 A, G, Q, R 값들로 아래의 필터를 만들 수 있다.
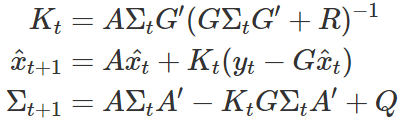 수식이 복잡하니 무슨 작업인지 좀 이해가 안 되겠지만, 쉽게 생각하면 이동평균처럼 중간 값들을 계속해서 찾아주는 작업이라고 보면 된다. 바퀴 움직임에 따라 예상되는 다음 바퀴의 움직임이나 로봇 청소기의 현재 위치의 범위를 구해놓고, 그 범위에 확률을 곱해서 가중평균된 값이 다음 바퀴의 움직임 & 로봇 청소기의 새로운 위치라고 정하는 것이다.
수식이 복잡하니 무슨 작업인지 좀 이해가 안 되겠지만, 쉽게 생각하면 이동평균처럼 중간 값들을 계속해서 찾아주는 작업이라고 보면 된다. 바퀴 움직임에 따라 예상되는 다음 바퀴의 움직임이나 로봇 청소기의 현재 위치의 범위를 구해놓고, 그 범위에 확률을 곱해서 가중평균된 값이 다음 바퀴의 움직임 & 로봇 청소기의 새로운 위치라고 정하는 것이다.
저 위에서 든 사기 클릭 데이터에 같은 필터를 적용시킬 때는 가중평균된 값이 기준 주기, 가중 평균과 실제 클릭 로그 값의 차이를 Noise라고 생각했었다.
최초 출발점 설정
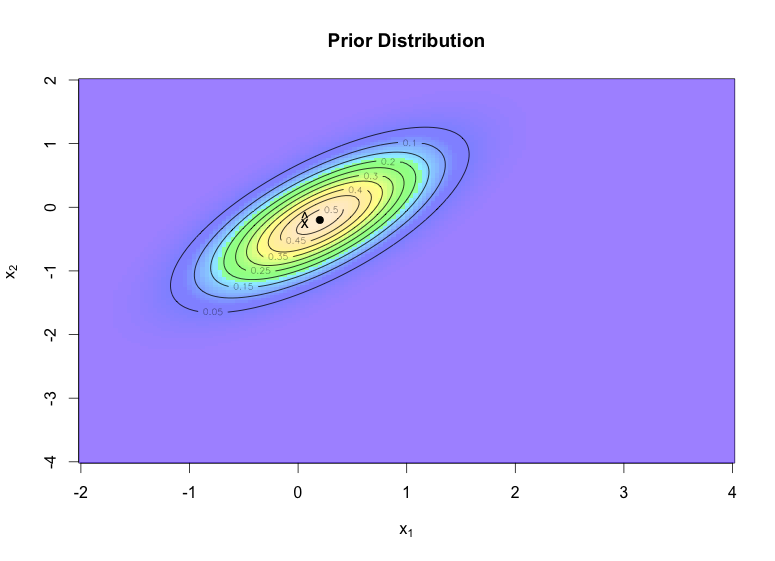
일단 단순하게 (가로, 세로) = (0.2, -0.2) 라고 생각해보자. 가로, 세로가 얼마나 많이 움직일지 (분산), 얼마나 많이 같은 방향으로 움직일지 (공분산)을 모아서 Covariance matrix를 만들고, 아래 코드에 Sigma = (0.4, 0.3, 0.3, 0.45)로 잡아놨다. 실제로 업무에 적용할 때는 기존의 측정 데이터를 활용하면 된다.
[code language=”r”]
# 출발점 (Prior) 기준의 예상되는 범위 – Prior distribution
library(mnormt)
xhat = c(0.2, -0.2)
Sigma = matrix(c(0.4, 0.3, 0.3, 0.45), ncol=2)
x1 = seq(-2, 4,length=151)
x2 = seq(-4, 2,length=151)
prior.density = function(x1,x2, mean=xhat, varcov=Sigma)
dmnorm(cbind(x1,x2), mean,varcov)
z = outer(x1,x2, prior.density)
mycols = topo.colors(100,0.5)
#그래프
image(x1,x2,z, col=mycols, main="Prior density", xlab=expression(‘x'[1]), ylab=expression(‘x'[2]))
contour(x1,x2,z, add=TRUE)
points(0.2, -0.2, col=’red’, pch=4, lwd=6)
text(0.1, -0.2, labels = expression(hat(x)), adj = 1)
[/code]
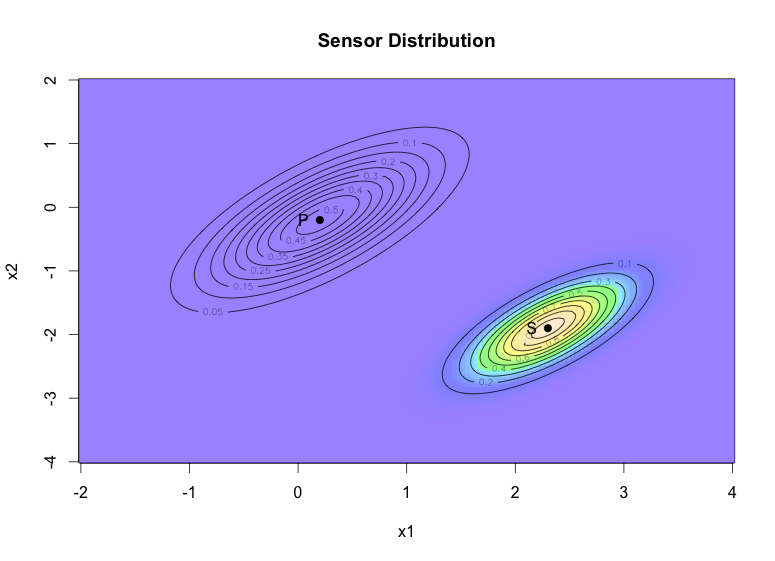
GPS 센서에서 받은 정보
![]()
y값은 시작 포인트를 (2.3, -1.9)로 잡고, 공분산(covariance)을 x의 절반으로 잡았다. (아래 코드 확인)
여기서 y가 G와 x에 의해 결정된다는 위의 식을 “수학”대신 “언어”로 풀어보면, x (바퀴 움직임)이 어느 정도일 때, y (GPS 센서)가 어느정도가 될 것이다는 조건을 이야기한다고 할 수 있다. 확률&통계적으로 말하면 “조건부 확률”이다. 아래 그래프는 G를 Identity matrix로 잡았을 때다.
[code language=”r”]
# 센서 정보 – 기본 셋팅
R = 0.5 * Sigma
z2 = outer(x1,x2, prior.density, mean=c(2.3, -1.9), varcov=R)
#그래프
image(x1, x2, z2, col=mycols, main="센서값에 따른 분포")
contour(x1, x2, z2, add=TRUE)
points(2.3, -1.9, col=’blue’, pch=4, lwd=6)
text(2.2, -1.9, labels = "y", adj = 1)
contour(x1, x2,z, add=TRUE)
points(0.2, -0.2, col=’red’, pch=4, lwd=6)
text(0.1, -0.2, labels = expression(hat(x)), adj = 1)
[/code]
필터링이란?
위의 두 작업을 통해서 x값들이 어떻게 움직이고 있는지, 주어진 x에 대해서 y값이 어떻게 반응하는지를 간단하게 모델화했다. 이제 x가 주어지면 y값을 (대략적으로) 알 수 있으니까, 반대로 y가 주어지면 x를 찾아보자. 어떻게? Bayesian을 활용한다.
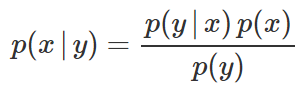
위 식을 이용해 현재 x값, y값, 그리고 x가 있을 때 y값을 알고 있으니, y가 주어졌을 때 x값이 얼마인지 추측할 수 있다.
그렇게 y가 주어졌을 때 x의 값과 분산을 구해보면,
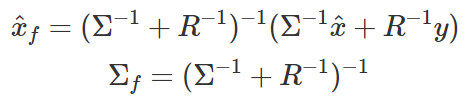
이런 전환 방식을 Bayesian에서는 Conjugate prior라고 부른다. 위의 값을 계산하는 방법은 여러가지가 있을테니 계산과정은 생략하고, x의 최종적인 범위를 보면,
[code language=”r”]
# 필터된 정보
G = diag(2)
y = c(2.4, -1.9)
xhatf = xhat + Sigma %% t(G) %% solve(G %% Sigma %% t(G) + R) %% (y – G %% xhat)
Sigmaf = Sigma – Sigma %% t(G) %% solve(G %% Sigma %% t(G) + R) %% G %% Sigma
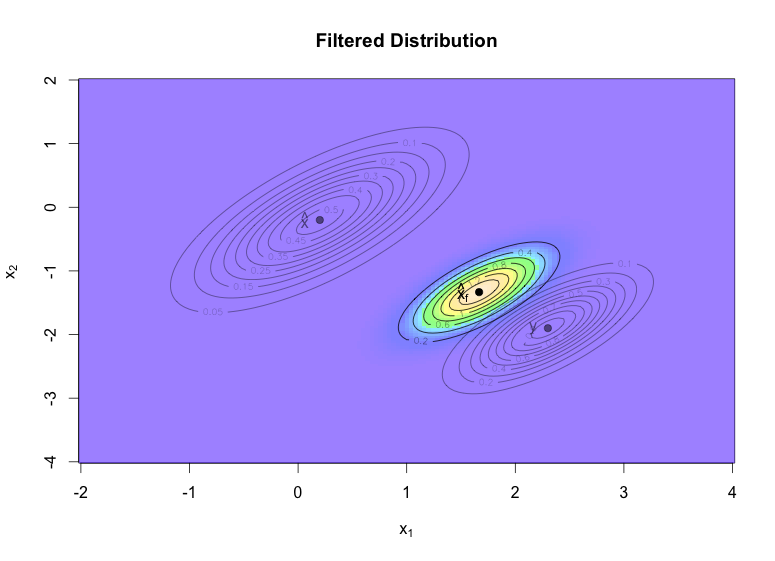
z3 = outer(x1, x2, prior.density, mean=c(xhatf), varcov=Sigmaf)
#그래프
image(x1, x2, z3, col=mycols, xlab=expression(‘x'[1]), ylab=expression(‘x'[2]), main="Filtered density")
contour(x1, x2, z3, add=TRUE)
points(xhatf[1], xhatf[2], pch=19)
text(xhatf[1]-0.1, xhatf[2], labels = expression(hat(x)[prior.density]), adj = 1)
lb = adjustcolor("black", alpha=0.5)
contour(x1, x2, z, add=TRUE, col=lb)
points(0.2, -0.2, col=’red’, pch=4, lwd=6)
text(0.1, -0.2, labels = expression(hat(x)), adj = 1, col=lb)
contour(x1, x2, z2, add=TRUE, col=lb)
points(2.3, -1.9, col=’blue’, pch=4, lwd=6)
text(2.2, -1.9,labels = "y", adj = 1, col=lb)
[/code]
위에서 노란색으로 반전된 분포를 베이지안 통계학에서 Posterior distribution 이라고 부른다. 다시 “수학”에서 “언어”로 표현 방식을 바꾸면, 로봇 청소기의 위치를 판별하는데 바퀴 움직임 정보와 GPS 정보를 결합할 때 GPS 정보가 좀 더 정확하다고 판단을 내린 것을 눈으로 확인할 수 있다. 실제 데이터로 작업할 때에는, 바퀴 움직임과 GPS 업데이트가 많아질수록 분산 값 (Q, R) 이 작아져서 분포 함수가 지금보다 덜 넓게 퍼질 것이고, 당연히 노란색의 결과값도 덜 퍼지게 된다. 또 계속해서 정보가 주어지면 x, y 중 어느 쪽에 더 가중치를 줄 것인지 (A, G)를 매번 조정할 수 있다.
이런 작업을 할 때, 머신러닝을 활용한다면 어떤 값에 손을 대야할까? Q, R은 데이터 포인트가 증가해야 조절되는 값이므로, A, G가 머신러닝 같은 (응용) 통계학 작업으로 조절할 수 있다는 감을 잡을 수 있을 것이다. 센서가 하나 밖에 없다면 머신러닝이 큰 의미가 없겠지만, 여러개의 센서가 제각각의 위치에서 보내주는 정보를 어떤 방식으로 결합하면 정확도가 더 올라갈지를 고민해본다면? 각 센서들에게 주는 가중치를 x, y 값의 레벨에 따라 다르게 작업할 수 있을텐데, 머신러닝은 딱 이런 포인트에 활용된다.
정리
내용을 요약하면, Noise가 많은 데이터를 필터링한 다음에, A에 대한 불확실한 정보와 A-B간 관계에 대한 정보를 이용해서 B로 A를 보정하는 모델을 만들었다. 이 때 A가 여러 소스에서 나온다면 (A1, A2, A3, …) 각각이 B에게 미치는 영향들을 결합해서 A1, A2, A3들이 상호 보정이 되도록 만들수도 있다. 이렇게 작업이 진행되기 때문에 필자가 줄곧 데이터 사이언스 프로젝트의 일부로 머신러닝을 활용한다고 표현하고, 그 속에는 깊이있는 통계학 지식이 필요하다고 주장하는 것이다.
나가며
요즘 회사에 CTO를 뽑겠다고 개발자들을 참 많이 만나고 다니는 중이다. (자신있으면 연락하시라 ㅎㅎ) 처음에는 VC가 왜 저렇게 깐깐하게 CTO의 학벌과 학력, 직장 경력, 프로젝트 포트폴리오, Challenge가 주어졌을 때 극복하는 방식 같은 내용들을 살펴보고, 왜 저렇게까지 민감한 이슈들을 확인하려고 하는지 잘 이해를 못했다. 개발자가 머신러닝하는 거 아니냐는 저급 VC들에게 투자받을 생각은 처음부터 없었던터라 실력없어보이는 VC는 모조리 대화를 끊었고, 개발은 그냥 SI성 개발 밖에 못 본데다, (듣는 개발자 기분 나쁘겠지만) 단순하게 벽돌 쌓는 막노동꾼과 개발자가 뭐가 다른가는 생각까지 했었기 때문이다. 만나봤던 꽤 많은 초짜 개발자들이 아카데믹 코딩만 했던 필자보다 개발 실력이 부족해서 회사가 피해를 입기도 했다. 그런 개발자들과 여러번 좌충우돌하면서 경험치가 쌓이고 나서야 개발이라는 걸 너무 왜곡된 시야로 봤구나는걸 깨닫게 되었다. 멀쩡한 설계도가 있는 집을 엉망으로 만드는 인테리아 업자들이 있듯이, 개발자들도 실력과 센스가 천차만별이더라.
몇 번 데어보고서야 비로소 개발자라는 직업군이 얼마나 다양한 “등급”이 있는지 절감하고, 왜 VC가 CTO에게 엄청난 스펙을 요구하는지 공감하게 됐다. Ad-Tech 회사라고 이름달고 있는 “좀 덩치커진” 스타트업들의 CTO들을 만나면서 공감은 확신이 되고 있는 중이다. 아마 데이터 사이언스 관련된 프로젝트를 주먹구구식으로 해보려는 개인이나 회사들도 마찬가지일 것이다. 이걸 단순한 개발 지식의 일부라고 생각하고 CTO에게 일임하고 있는 CEO나, 깊이 없이 코드 Copy & Paste해서 쓰는 CTO들이 모델링이라는 관점을 이해하려면 몇 번 당해봐야겠지. 아니면 그저그런 CTO로 회사 성장의 한계에 다달은 Ad-Tech 회사들처럼 모델링을 제대로 하는 영역에 영원히 진입하지 못하던가.
참고로, 90년대 말에 파생상품 하나 잘못 사서 JP Morgan에 3천억을 갖다바친 국내의 어느 대기업 계열 증권사는 20년이 지난 요즘도 제대로 파생상품을 이해하는 사람을 못 뽑고 있더라. 심지어 그 대기업 오너는 큰 손실의 기억이 채 가시기도 전인 2000년대 초반에 회사 돈으로 파생상품 투자(?)를 하다가 천억도 넘는 손실을 보고 횡령 혐의로 곤욕을 치르기도 했다. 이젠 좀 배우셨을라나?









